 Map
Map


HTML
-
由于石油存储量的减少和开采以及燃烧对环境污染问题的加剧,传统的汽油和柴油的使用面临着巨大挑战。具有清洁、对环境污染小等优点的甲醇汽油、乙醇汽油作为一种可替代的能源,受到了越来越多的重视[1-4]。
甲醇汽油和乙醇汽油的使用能够有效地降低一氧化碳和有毒气体的排放,减少对环境的污染。目前市场上的低浓度醇类汽油可以直接替代传统汽油进行使用,当甲醇体积分数达到0.85以上,则称为高浓度甲醇汽油[5]。
由于甲醇和乙醇的理化性质并不完全相同,因此配制而成的甲醇汽油和乙醇汽油也存在很多不同的特性[6-8],甲醇汽油的热量值高,但甲醇有一定的腐蚀性,乙醇汽油热量值相对较低,但是乙醇汽油燃烧更加稳定,因此对醇类汽油进行定性判别显得非常重要[9]。此外,醇类汽油相对于传统汽油来说热值较低,当汽油中醇体积分数过高时会导致发动机动力不足,同时过量的甲醇、乙醇燃烧容易产生气阻,影响系统供油,从而对发动机的气密性产生不良影响,所以汽油中甲醇、乙醇的体积分数是汽油品质的一个重要的衡量指标[10],因此寻找一种高效、准确的方法来快速测定汽油中甲醇、乙醇体积分数[11]显得尤为重要[12-13]。
近年来,国内外学者做了大量的光谱分析研究。LIU等人[14]通过近红外和喇曼光两种光谱分别建立了甲醇汽油中甲醇含量的偏最小二乘(partial least square, PLS)模型, 实验结果表明,同样在PLS模型的建立下,应用近红外光谱技术获得的结果更好。YAO等人[15]采用喇曼检测技术检测甲醇汽油,针对喇曼特征峰建立甲醇含量的一元线性回归模型,实验结果表明,使用喇曼特征峰所需样本数更少且模型具有良好的精度和稳健性。OUYANG等人[16]采用中红外光谱技术结合最小二乘支持向量机来测定甲醇柴油中甲醇含量,实验结果表明,应用中红外光谱技术和偏最小二乘-最小二乘支持向量机(partial least square-least square support vector machine, PLS-LSSVM)可以快速检测甲醇柴油中的甲醇含量。
当前的研究更多是对单一类型的醇类汽油进行分析,而且模型也不具有通用性,针对不同的汽油需要重新进行测定和建模,并且模型数据处理速度较慢, 因此建立一种通用模型来对醇类汽油进行定性定量分析显得尤为重要。
本文中采用中红外光谱技术,通过对比分析醇类汽油的光谱图,找到一种同时适合甲醇汽油和乙醇汽油检测的模型。首先建立不同预处理后的甲醇、乙醇含量的通用PLS模型[17],为进一步简化模型,结合无信息变量消除(uninformation variable elimination, UVE)波段筛选算法[18],基于UVE-PLS[19]和UVE-LSSVM[20]两种方法分别建立甲醇汽油和乙醇汽油的通用模型,并对两种建模效果进行评价,从而找到一种最适合测定甲醇汽油和乙醇汽油中醇含量的通用模型。
-
本实验中的汽油为某加油站购买,汽油为93#,实验用的无水甲醇、无水乙醇的体积分数不小于0.997。样品在配制时,按照0.008的梯度进行配制,其体积分数范围从0.008~0.25。先按照相应梯度计算不同比例下甲醇的体积,然后将对应的甲醇加入到容量瓶,再用汽油进行滴定至50mL, 振荡均匀,直至液体不分层,配制30个不同体积分数的甲醇汽油溶液。按照相同方法,配制30个不同体积分数的乙醇汽油溶液。每个体积分数配制4个样品,共得到甲醇汽油、乙醇汽油样品各120个。
-
本实验中采用WQF-510A傅里叶变换红外光谱仪与OPUS光谱采集软件配套使用,样品的中红外光谱由此采集获得,实验的环境温度调到25℃左右,湿度调到50%以下,测量范围为仪器的扫描范围(4000cm-1~6000cm-1),分辨率优于0.85cm-1,扫描时间为32s,机器预热30min后才可以进行检测操作。每次采集光谱时,取1mL甲醇汽油溶液均匀滴在硒化锌晶体片上,关紧仪器舱门,进行光谱采集。数据处理在UNSCRAMBLER(verion.10.1;CAMO)分析软件中进行,所有程序均在MATLAB R2012a中编辑与运行。为减少因样品挥发等因素对实验结果的影响,每个样品分别采集5条光谱,用5条光谱的平均光谱来建模。
-
偏最小二乘法在光谱检测中运用比较成熟,本文中先对采集到的原始光谱进行预处理,然后建立PLS模型,对其进行评价,再对其进行UVE波段筛选后,采用PLS和LS-SVM建立光谱模型,其中,建模集和预测集数量比为3:1。建模集样品用于建立模型,验证集样品用于对模型的验证。
采用MATLAB软件处理数据和建立模型。图 1为醇类汽油醇含量检测模型建立的流程图。醇类汽油中醇含量PLS模型建模效果好坏用预测集决定系数R2和预测集均方根误差(root mean square error of prediction, RMSEP)来评价,PLS模型的决定系数越高,预测均方根误差越小, 则表明模型的精度越高,而且建模集均方根误差(root mean squacre error of construction, RMSEC)与RMSEP两者差值越小,说明模型的稳定性越好,RMSEC和RMSEP公式如下式所示:
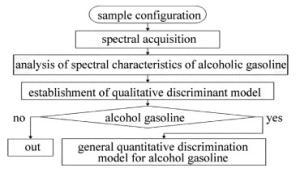
Figure 1. Flow chart of alcohol content detection model for alcoholic gasoline
式中,n为样品总数,nc为建模集样品个数,np为预测集样品个数,yi,c为建模集第i个样品的真实值,yi,p为预测集第i个样品的预测值。
-
偏最小二乘法是以主成分(principal component, PC)分析作为数学基础并基于因子分析的一种多变量的校正方法。它常用于建立试验样品的光谱矩阵与样品体积分数之间的关系。PLS模型的预测原理如下式所示:
式中, A是所建立模型的预测值,i表示的是第i个波长点,βi表示的是第i个波长点对应的回归系数的数值,λi表示的是第i个波长点对应的光谱能量的数值,m为波长点的数量,B为所建立模型的截距。
-
偏最小二乘支持向量机是针对小样本建立的统计学方法,其常用的核函数是线性核函数和径向基核函数。线性核函数公式为:
非线性核函数公式为:
式中, xi为样本点,xj为样本的中心点,γ为分布参量,σ2为内核参量,K表示径向基函数的方差。
1.1. 实验材料
1.2. 光谱采集
1.3. 模型评价标准
1.4. 算法原理
1.4.1. 偏最小二乘法
1.4.2. 偏最小二乘支持向量机
-
为了减小实验仪器因振动、噪声以及温度等产生的影响,对采集的光谱进行适当预处理很有必要,合适的预处理以获得较好的建模效果。将采集到的甲醇汽油的中红外光谱经预处理后得到的数据作为模型的输入变量X,甲醇体积分数作为输出变量Y,建立了偏最小二乘模型,其结果如表 1所示。由比较可知, 光谱经过平滑处理后建模效果最好。此时,模型的预测集相关系数rp=0.890,预测集均方根误差RMSEP为3.035。而经过多元散射校正、和归一化处理后的建模效果均低于用原始光谱建模效果,此时预处理对建模结果不但没有优化反而降低了模型的预测精度。
model preprocessing PC construction prediction rc RMSEC rp RMSEP PLS original 12 0.946 2.164 0.883 3.127 processing 14 0.962 1.816 0.890 3.035 multivariate scattering calibration 12 0.961 1.837 0.875 3.228 baseline 8 0.962 1.808 0.888 3.061 normalization 8 0.953 2.008 0.869 3.294 Table 1. Results of PLS model for alcohol content of alcoholic gasoline
-
图 2为甲醇汽油和乙醇汽油中红外原始光谱。从波形来看,甲醇汽油和乙醇汽油中红外原始光谱有用信息主要集中在1500cm-1~2750cm-1和3050cm-1~3500cm-1范围内,由于光谱两端存在噪声信息,故建模时候选取1500cm-1~3500cm-1的波段。图中甲醇汽油和乙醇汽油中红外原始光谱波形是一致的,只是在一定的波段内的光强有区别。这是由于甲醇汽油和乙醇汽油中分别含有甲醇和乙醇,同样含量的乙醇汽油中红外的透射更高。
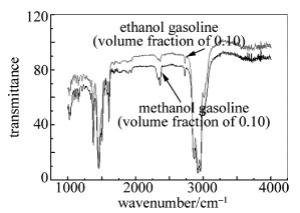
Figure 2. Middle infrared original spectrum of methanol gasoline and ethanol gasoline
-
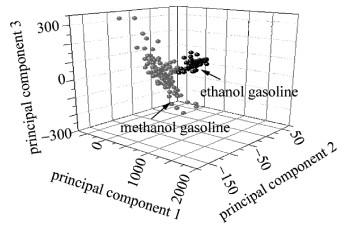
采用全谱进行主成分分析,将采集的光谱压缩成若干的主成分的线性组合,前3个主成分的得分如图 3所示。甲醇汽油和乙醇汽油出现聚类,图中甲醇汽油120个样品,乙醇汽油120个样品,通过主成分发现:第一主成分的累计贡献率为88%,第二主成分的累计贡献率为11%,第三主成分贡献率为1%。通过主成分分析就可以方便地将240个样本简单的分成两类。
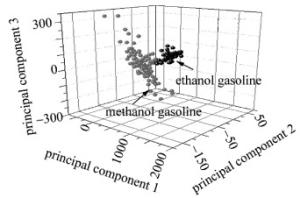
Figure 3. Scattering point map of PC numberss
-
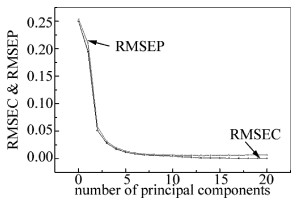
将甲醇汽油和乙醇汽油分别单独进行随机划分,按照3:1进行挑选建模集和预测集,其中,甲醇汽油和乙醇汽油分别有建模集90个,预测集30个,分别将甲醇汽油和乙醇汽油的建模集合并为一个大的建模集180个样本,将甲醇汽油和乙醇汽油的预测集合并为一个大的预测集60个样本。通过UNSCRAMBLER 8.0软件建立定性偏最小二乘判别(discriminant partial least square, DPLS)模型,图 4为醇类汽油醇含量RMSEC和RMSEP随主成分因子数的变化曲线。建模时主成分因子数有很重要的作用,若建模时选择PC为5或者小于5,就可能因为一些有效信息被忽略导致模型精度降低,出现“欠拟合”现象;若建模时选择过高,又会因为噪声信号等影响而产生“过拟合”现象,故由图 4可知, 本实验中DPLS模型最佳主成分因子数(PC)为6。

Figure 4. Relationship between RMSEC & RMSEP and PC number of DPLS model
定性偏最小二乘判别法(DPLS)是将定量偏最小二乘法用于判别分析并建立中红外光谱特征与样本分类变量之间的回归模型的一种定性判别方法。主要思想就是用样品的分类向量代替样品的体积分数向量,再通过定量偏最小二乘方法建立模型。分类向量设为[1, 2],其中1为乙醇汽油样品,2为甲醇汽油样品。
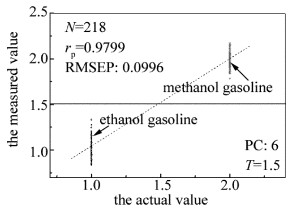
图 5所示为预测集样品(包括甲醇汽油和乙醇汽油两种)分类变量的DPLS模型回归图。建模样品60个,RMSEP为0.0996,相关系数rp=0.9799,波长变量N=218。取阈值T=1.5,线性回归模型建模有0个甲醇汽油样品误判为乙醇汽油样品,误判率为0%。
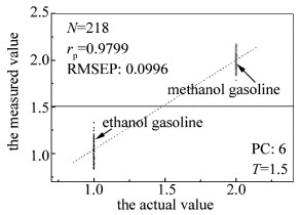
Figure 5. Regression model diagram of prediction set of DPLS model
-
以全波段的光谱数据作为输入变量,数据较多,数据处理耗时长。选择一种适当的波长筛选方法,不仅可以缩短建模时间,还能提高建模的预测精度。此外可以避免光谱仪的噪声影响, 以及一些波长对外界环境因素变化敏感,去掉冗余信息提高数据的处理速度。
对光谱进行波段筛选是一种非常有效的光谱处理方法,能够大大优化模型,本文中采用UVE方法。该方法的原理是基于PLS回归系数建立的波段筛选方法,将回归系数作为重要衡量指标,此法将一定数目的随机变量矩阵加入光谱矩阵中,再通过交互验证建立PLS模型,通过计算PLS与回归系数的平均值与标准偏差比值来选取有效光谱信息,此法将噪声信号和体积分数信息集于一体,方便和直观。
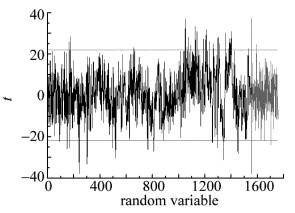
在全谱范围内采用UVE方法进行变量优选。图 6为UVE变量稳定性的分析结果。横坐标为随机变量,纵坐标t为回归系数的平均值与标准偏差的比值。垂直实线为波长变量和随机噪声变量的分割线,左边为波长变量,右边为噪声变量。变量稳定性值位于两阈值之间的波长变量为无用信息变量,需要被剔除;处于量阈值之外的波长变量为有用信息变量,需要保留。通过UVE波段筛选变量后共有236个波长变量被选择。以筛选的波长点所含信息作为输入变量建立更加简化的模型。

Figure 6. Relationship between t and random variables
-
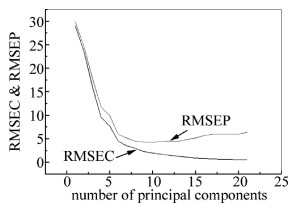
偏最小二乘法可以充分利用小样本包含的信息,本实验中它可以充分利用醇类汽油光谱数据与中醇含量之间的线性关系关系来建立模型。图 7为甲醇含量建模和预测集均方根误差随主成分因子数变化曲线图。因此,在本实验醇类汽油的醇含量PLS模型中,最佳主成分因子数为7。UVE-PLS模型的预测效果为:预测集R2和RMSEP分别为0.902, 2.591。
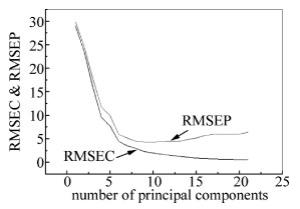
Figure 7. Relationship between RMSEC & RMSEP and PC number of UVE-PLS model
-
在UVE-LSSVM建模中,采用线性核函数(linear kernel, LIN)和径向基函数(radical basis function, RBF)分别建立支持向量机模型,分别比较两种函数的建模效果,结果表明:采用LIN核函数时,惩罚因子γ=1.2128,其预测集R2和RMSEP分别为0.8704, 3.2810,采用RBF时,该模型有两个重要参量:惩罚因子γ和核参量σ2,这两个未知参量在一定意义上影响模型泛化能力和建模效果。通过多次尝试,确定了模型的两个参量,此时UVE-LSSVM模型参量的最佳组合为:γ=784.115, σ2=127.973, 其预测集R2和RMSEP分别为0.945, 2.187。通过对比,发现选用RBF更加有利于模型的建立。
-
从表 2可以得出,在两种不同建模方法中,UVE-LSSVM取得最好的结果。通过对比,UVE-PLS的预测集R2和RMSEP分别为0.902, 2.591,UVE-LSSVM的预测集R2和RMSEP分别为0.945, 2.187。结果表明,在甲醇汽油和乙醇汽油中醇类含量检测方面,应用中红外光谱技术结合UVE-LSSVM组合模型可以快速准确地预测甲醇汽油中甲醇含量以及乙醇汽油中乙醇含量,为进一步研究醇类汽油其它指标奠定了基础。
model prediction R2 RMSEP UVE-PLS 0.902 2.591 UVE-LSSVM 0.945 2.187 Table 2. Prediction results by UVE-PLS and UVE-LSSVM
2.1. 醇类汽油中醇类含量光谱校正处理
2.2. 甲醇、乙醇汽油定性判别模型
2.2.1. 甲醇汽油和乙醇汽油光谱对比

2.2.2. 样本判别分析模型
2.2.3. 偏最小二乘判别分析
2.3. 醇类汽油的醇含量光谱定量模型对比
2.3.1. 醇类汽油的醇含量光谱建模变量筛选
2.3.2. UVE-PLS模型的建立
2.3.3. UVE-LSSVM模型的建立
2.3.4. UVE-PLS和UVE-LSSVM模型对比
-
通过中红外光谱技术建立了甲醇汽油、乙醇汽油的定量分析通用模型,实验结果较为理想。研究结果表明:利用主成分分析和偏最小二乘判别法对甲醇汽油和乙醇汽油样品定性判别效果明显,样品检测准确率达到100%;其次甲醇汽油、乙醇汽油其醇类含量通用模型的最优模型为UVE- LSSVM,预测集R2和RMSEP分别为0.945, 2.187。相比于以往的单一模型研究来说,本文中的通用模型在不知道汽油类型的情况下,可以先对汽油进行定性判别,然后再对汽油中所含醇的含量进行测定, 避免了单一模型检测甲醇汽油、乙醇汽油时需要分别建模的缺点,同时模型的稳定性相对较好;但是在定量检测的精度上,与单一模型对比,建模精度稍差一点,但本文中的通用模型仍然是一种对甲醇汽油和乙醇汽油进行定量分析的好方法,此方法能够为醇类汽油生产厂家提供一种新的含量检测方法,具有较强的现实意义。
 DownLoad:
DownLoad: